안드로이드로 공적 마스크 데이터를 가져오는 앱을 개발하다면서 공적 마스크 데이터를 처음 봤습니다.
API에서는 실시간 데이터만 제공하고 10분마다 업데이트 된다는 것을 알았습니다.
문득 이 데이터들을 저장하면 나중에 머신러닝 할 때 써먹을 수 있지 않을까라는 생각이 들어서 간단하게 파이썬으로 공적 마스크 데이터를 가져오고 CSV파일로 저장하는 코드를 작성해봤습니다.
그리고 데이터가 10분마다 업데이트 되기 때문에, 10분마다 데이터를 가져오고 저장하도록 자동화해봤습니다.
공적 마스크 데이터에 대한 설명은 이전 포스팅을 참고해주세요. 이번 포스팅에서는 생략했습니다.
1. 공적 마스크 데이터 가져오기
먼저 공적 마스크 판매처 데이터를 저장했습니다.
urlopen과 json을 사용해서 데이터를 가져오고 Json으로 파싱해봤습니다.
from urllib.request import urlopen
import json
url = "https://8oi9s0nnth.apigw.ntruss.com/corona19-masks/v1/stores/json?page=1"
responseBody = urlopen(url).read().decode('utf-8')
jsonArray = json.loads(responseBody)
storeInfosArray = jsonArray.get("storeInfos")
print(storeInfosArray)결과의 맨 마지막을 보면 아래와 같이 나와있습니다.
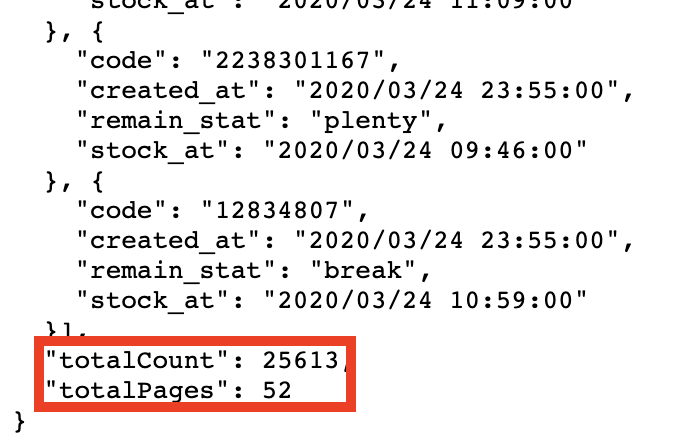
공적 마스크 판매처가 총 26613 곳인데 첫번째 페이지에서는 488개만 알려줬습니다.
perPage가 default로 500이기 때문에 한 페이지당 500개 이하로만 넘겨줍니다.
나머지 2~52페이지에서 데이터를 가져와야합니다.
from urllib.request import urlopen
import json
url = "https://8oi9s0nnth.apigw.ntruss.com/corona19-masks/v1/stores/json?page="
responseBody = urlopen(url+"1").read().decode('utf-8')
jsonArray = json.loads(responseBody)
storeInfosArray = jsonArray.get("storeInfos")
numPage = jsonArray.get("totalPages")
print(storeInfosArray)
for i in range(2,numPage+1):
responseBody = urlopen(url+str(i)).read().decode('utf-8')
jsonArray = json.loads(responseBody)
storeInfosArray = jsonArray.get("storeInfos")
print(storeInfosArray)
2. CSV 파일로 저장
csv 라이브러리를 사용해서 addr, code, lat, lng, name, type column으로 나눠서 저장했습니다.
from urllib.request import urlopen
import json
import csv
def getFirstPageJsonAreray(url):
responseBody = urlopen(url).read().decode('utf-8')
jsonArray = json.loads(responseBody)
storeInfosArray = jsonArray.get("storeInfos")
numPage = jsonArray.get("totalPages")
return storeInfosArray, numPage
def getJsonArray(url):
responseBody = urlopen(url).read().decode('utf-8')
jsonArray = json.loads(responseBody)
storeInfosArray = jsonArray.get("storeInfos")
return storeInfosArray
def saveCSV(w, jsonArray):
for i in range(0,len(jsonArray)):
temp = jsonArray[i]
w.writerow([temp.get("addr"), temp.get("code"), temp.get("lat"), temp.get("lng"), temp.get("name"), temp.get("type")])
def main():
f = open('공적마스크데이터.csv','w',encoding='utf-8-sig',newline='')
w = csv.writer(f,delimiter=',')
url = "https://8oi9s0nnth.apigw.ntruss.com/corona19-masks/v1/stores/json?page="
jsonArray, numPage = getFirstPageJsonAreray(url+"1")
saveCSV(w, jsonArray)
for i in range(2,numPage+1):
jsonArray = getJsonArray(url+str(i))
saveCSV(w, jsonArray)
f.close()
if __name__ == '__main__':
main()
잘 저장 되었습니다.
공적 마스크 판매처 정보를 저장했으니, 이제는 공적 마스크 재고 및 입고 데이터를 가져와서 csv 파일로 저장해보겠습니다.
Sales 정보는 아래 url에서 볼 수 있습니다.
https://8oi9s0nnth.apigw.ntruss.com/corona19-masks/v1/sales/json
위 코드를 조금만 변형하면 됩니다.
from urllib.request import urlopen
import json
import csv
def getFirstPageJsonAreray(url):
responseBody = urlopen(url).read().decode('utf-8')
jsonArray = json.loads(responseBody)
storeInfosArray = jsonArray.get("sales")
numPage = jsonArray.get("totalPages")
return storeInfosArray, numPage
def getJsonArray(url):
responseBody = urlopen(url).read().decode('utf-8')
jsonArray = json.loads(responseBody)
storeInfosArray = jsonArray.get("sales")
return storeInfosArray
def saveCSV(w, jsonArray):
for i in range(0,len(jsonArray)):
temp = jsonArray[i]
w.writerow([temp.get("code"), temp.get("created_at"), temp.get("remain_stat"), temp.get("stock_at")])
def main():
f = open('공적마스크Sales.csv','w',encoding='utf-8-sig',newline='')
w = csv.writer(f,delimiter=',')
url = "https://8oi9s0nnth.apigw.ntruss.com/corona19-masks/v1/sales/json?page="
jsonArray, numPage = getFirstPageJsonAreray(url+"1")
saveCSV(w, jsonArray)
for i in range(2,numPage+1):
jsonArray = getJsonArray(url+str(i))
saveCSV(w, jsonArray)
f.close()
if __name__ == '__main__':
main()
3. 10분마다 가져오기
threading 라이브러리를 사용해서 10분(=600초) 마다 한번씩 가져오도록 했습니다.
파일 이름은 현재 날짜 및 시각을 가져와서 저장해 중복되지 않도록 했습니다.
from urllib.request import urlopen
from datetime import datetime
import json
import csv
import threading
def getFirstPageJsonAreray(url):
responseBody = urlopen(url).read().decode('utf-8')
jsonArray = json.loads(responseBody)
storeInfosArray = jsonArray.get("sales")
numPage = jsonArray.get("totalPages")
return storeInfosArray, numPage
def getJsonArray(url):
responseBody = urlopen(url).read().decode('utf-8')
jsonArray = json.loads(responseBody)
storeInfosArray = jsonArray.get("sales")
return storeInfosArray
def saveCSV(w, jsonArray):
for i in range(0,len(jsonArray)):
temp = jsonArray[i]
w.writerow([temp.get("code"), temp.get("created_at"), temp.get("remain_stat"), temp.get("stock_at")])
def main():
now = datetime.now()
strNow = str(now.year) + str(now.month) + str(now.day) + " " + str(now.hour) + ":" + str(now.minute) + ":" + str(now.second)
f = open('sales_'+str(now)+'.csv','w',encoding='utf-8-sig',newline='')
w = csv.writer(f,delimiter=',')
url = "https://8oi9s0nnth.apigw.ntruss.com/corona19-masks/v1/sales/json?page="
jsonArray, numPage = getFirstPageJsonAreray(url+"1")
saveCSV(w, jsonArray)
for i in range(2,numPage+1):
jsonArray = getJsonArray(url+str(i))
saveCSV(w, jsonArray)
f.close()
def thread10min():
main()
threading.Timer(600, thread10min).start()
if __name__ == '__main__':
thread10min()
폴더 내에 아래와 같이 저장됩니다.
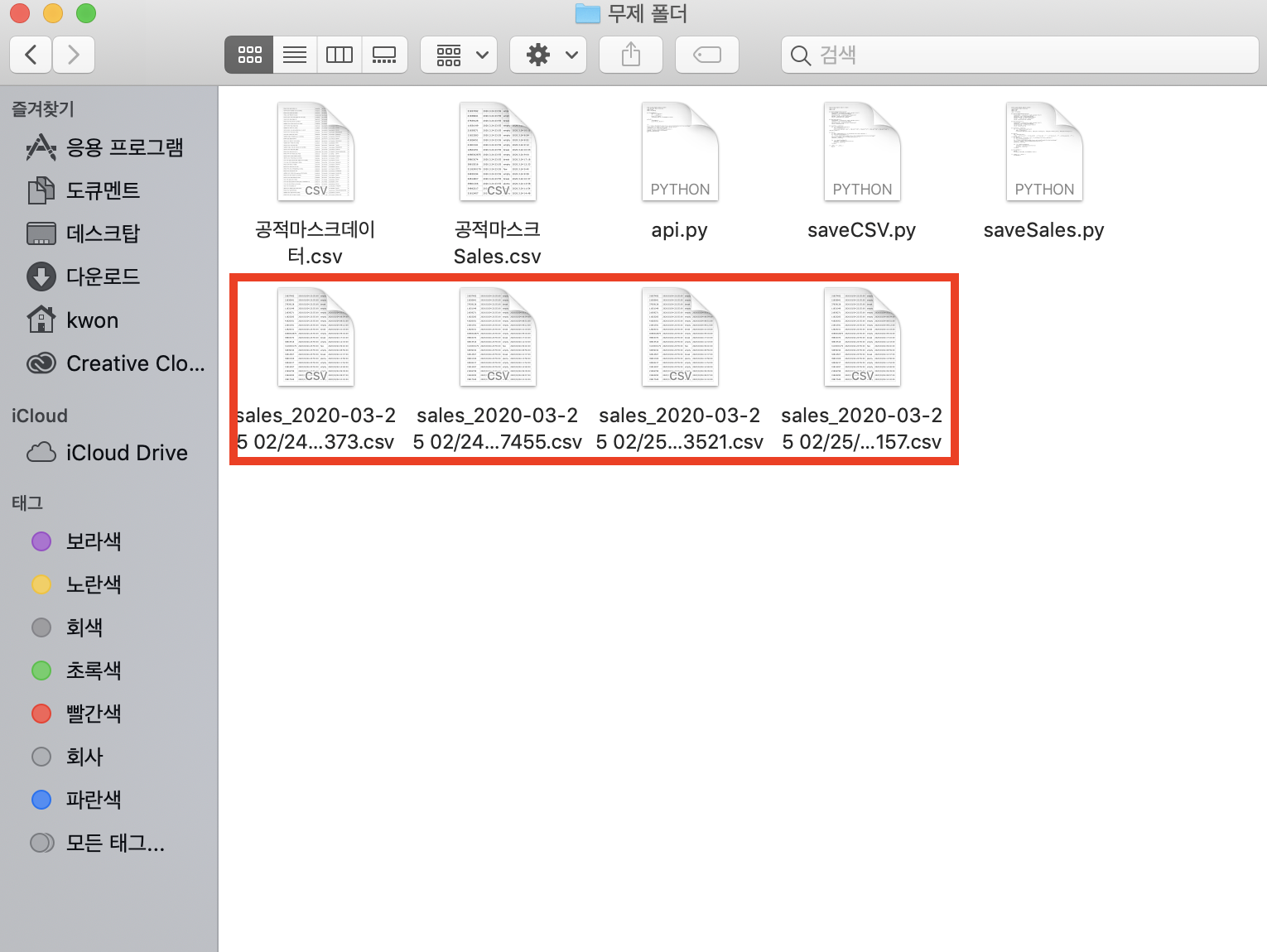
파이썬에서 thread를 사용한건 처음이어서 조금 헤맸습니다.
다 작성하고 보니 저만 알아보게 코드를 짠 것같기도 합니다.
시간내서 파이썬 코딩 스타일을 공부해야겠네요ㅠㅅㅜ
잘못된 내용이 있다면 언제든지 댓글이나 메일로 알려주시면 감사하겠습니다.
이 포스팅이 도움이 되었다면 공감 부탁드립니다.
궁금한 점은 언제든지 댓글 남겨주시면 답변해드리겠습니다:D
'major > Python' 카테고리의 다른 글
| 파이썬 문서화하기 - docstring (0) | 2020.04.18 |
|---|---|
| 파이썬으로 가우시안 필터링하기 (3) | 2020.04.17 |
| 파이썬으로 REST API 개발하기 - Django (1) | 2020.04.07 |
| 맥(macOS)에서 파이썬 윈도우 실행파일 만들기 (2) | 2020.02.24 |
| 파이썬 트위터 크롤링하기 - twitterscraper (20) | 2020.02.23 |



